
You can get data from a website by parsing Html or XML structures with the Python BeautifulSoup library.
Nowadays, web scraping is becoming more and more important as a lot of data is moved on websites. This article is made to show you the web scraping process.
What is Web Scraping?
HTML or XML codes, which are the building blocks of websites, are in a certain order and the process of extracting data from these codes is called web scraping.
Steps of Web Scraping
In general, there are certain steps in web scraping that will help you scrape data, but sometimes these rules can be bent.
While they differ from project to project, these steps apply to almost any project, but some steps can be skipped or stretched if they’re not suitable for your project.
- Decide what data you need
- Learn the format of the data
- Identify the sources from which you can obtain the data (check if it is variable)
- Check if data needs clearing
- Store your data
If you can answer these questions, you can start scraping data. Below are the steps you need to do to scrape data.
- Step 1: Research the website from which the data will be acquired.
- Step 2: Start building the bot that will scrape the data
- Step 3: Clean, process, store extracted data
Is Web Scraping Legal?
One question you may have is whether web scraping is legal or not, let’s talk about it briefly in this section.
The legality of web scraping is up to the owner of the website, so you can scrape if the admin hasn’t banned it, if the admin has, you can’t.
You can check whether it is allowed or not by typing /robots.txt at the end of the targeted website.
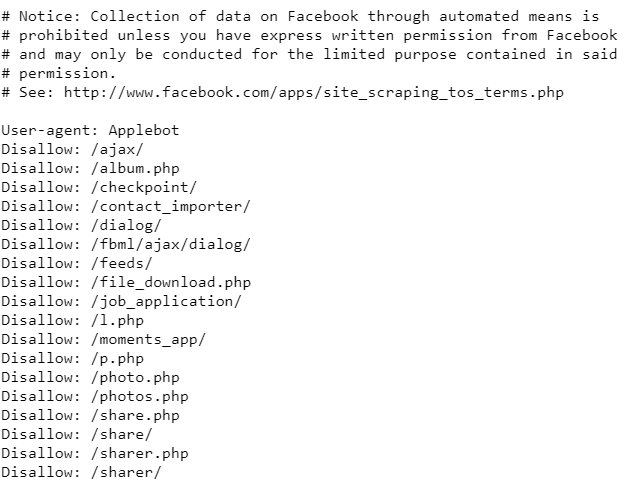
As you can see, Facebook has stated that web scraping is not allowed with the Robots.txt file. If you try to scrape it, legal action may begin.
Installation of Libraries
To do web scraping on Python we need several libraries: requests and beautifulsoup4, if PIP is installed, you can install both with the commands below.
pip install beautifulsoup4
pip install requests - BeautifulSoup = It is used to access the HTML codes of the website and perform web scraping.
- requests = It allows us to connect by sending a request to the website.
Step by Step Web Scraping
In this section, we will see step by step how to scrape a website and how to store the excavated data.
Step 1 – Find Website (Data)
In this section, we will get the data of IMDB’s top 250 movies, which you can access by clicking this link.
Before starting other scraping processes, also analyze the website and search for websites that store the data you want.
Now that we have determined what data we want and our website, we can proceed to the scraping process.
Step 2 – Web Scraping
In this section, we will learn to get the desired data from the target website, so the main topic of this article will be covered in this step.
1 – Connect Website
Let’s send a request to connect to the website with the request library. Thanks to this, we can take action on the website.
Url = "https://www.imdb.com/chart/top/"
web = requests.get(Url)2 – Parsing the Page
Since we will get the data through the HTML codes of the site, we need to parse the HTML codes of the site, we can use an HTML parser for this.
soup = BeautifulSoup(web.content, "html.parser")
print(soup.prettify())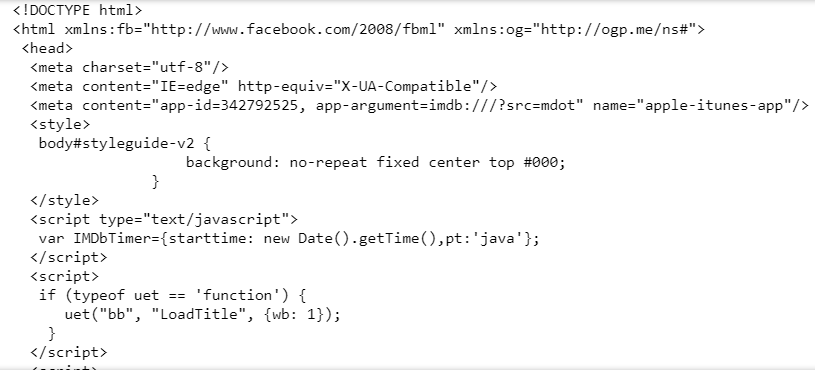
All the codes of the site are assigned to the variable named soup, let’s use the soup variable to get the block where only the data is stored.
Prettify function use this function when you need to display HTML blocks that organized to make them easier to read
3 – Cleaning Unnecessary Codes
We don’t need all the code on a web page, we just need to get the class the data is in. In this section, we will clean the unnecessary partitions.
To see in which block the data is stored, open the inspector from the web browser (right-click, inspector at the bottom)
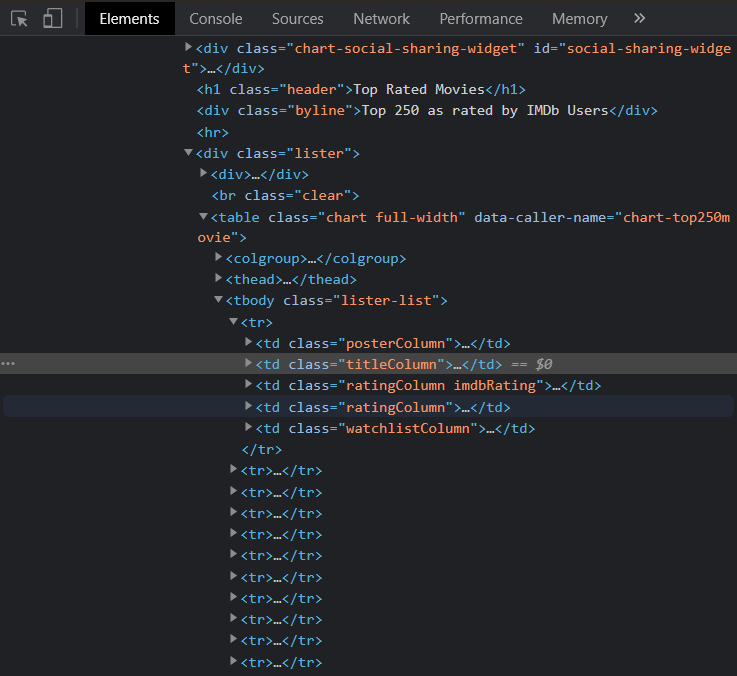
Let’s start by getting the title data, the title data is hosted in the class named titleColumn we can separate this data from the main HTML code.
titleClass = soup.find_all("td" , class_= "titleColumn")find_all is used to parse the specified class and everything else below it, since this is a returnable value, you must use a loop to obtain the structures.
We have to parse the link block inside the TitleColumn class, then convert the linked text to a string and assign it to a variable.
# Find All Link in titleColumn
# Store Link Name in List
titles = []
for tag in titleClass:
link = tag.find_all("a" , href = True)
for tag in link:
titles.append(tag.text)Let’s summarize the algorithm here with the list below so that we can understand the find_all function more easily.
- Get all code blocks under titleClass.
- Parse the text inside each block with the help of a loop.
- Add parsed texts (headings) to a list
ratingClass = soup.find_all("td" , class_="ratingColumn")We will parse the main class again to get the rating points, and we will apply the same operations in this class.
# Split blocks containing strong
# Get text in allocated blocks
# Convert Float
ratings = []
for tag in ratingClass:
rating = tag.find_all("strong")
for j in rating:
ratings.append(float(j.text))We got all the data we need, we need to store this data for later use, with the help of Pandas we can store the data in CSV.
3 – Store Got Data
We can convert the data to a CSV or XLSX file for later use without the need to scrape the data again.
In this section, we will convert the data obtained with Pandas to DataFrame, so when you want to analyze, you can easily start your analysis by calling the file.
# Convert List to DataFrame
import pandas as pd
data = pd.DataFrame(zip(name , ratings),
columns = ["Name" , "Ratings"])Now let’s quickly check the data we received on the Pandas DataFrame.
# Show Data
data.head(10)
Yes, we have successfully completed the web scraping process, we pull the data on the website and store it in a DataFrame.
If you want direct access to the data without re-scraping, you can convert the DataFrame to a CSV file and call it with the help of Pandas.
data.to_csv("file_name.csv")
Wow, awesome article, as a non-tech user I am using e-scraper.com – an on-demand web scraping service for eCommerce use.
Thank you for the auspicious writeup. It in fact was a amusement account it. Look advanced to far added agreeable from you! By the way, how can we communicate?
Remarkable! Its actually awesome article, I have got much
clear idea regarding from this paragraph.
Hmm is anyone else experiencing problems with the images on this blog loading?
I’m trying to find out if its a problem on my end or if it’s
the blog. Any feed-back would be greatly appreciated.
Hello, we are working on the problem and it will be solved in a short time.
What’s up colleagues, nice article and nice arguments commented here, I am actually enjoying by these.
I appreciate you sharing this blog article.Really thank you! Keep writing.
Its like you read my mind! You seem to know so
much about this, like you wrote the book in it or something.
I think that you could do with a few pics to drive the message home a little bit,
but other than that, this is excellent blog. A great read.
I’ll definitely be back.
I’m not that much of a online reader to be honest but your blogs really nice,
keep it up! I’ll go ahead and bookmark your site to come back later
on. Many thanks